반응형

현상
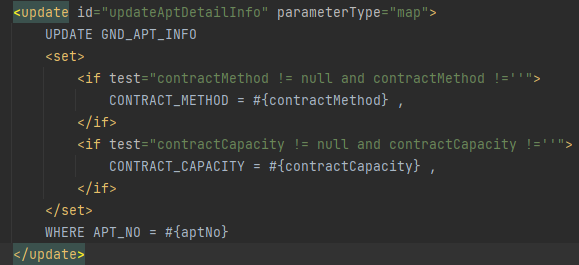
ChargeUtil chargeUtil = new ChargeUtil();
이런식으로 chargeUtil 의 내부 메소드로 application.properties에 정의되어 있는 값을 @value로 가져오는데
모든 값이 null 로 나오는 상황
원인
new를 이용해 클래스를 인스턴스화 하면 스프링이 관여하지 않아 어노테이션(@value)이 무시됨
참고 : https://stackoverflow.com/questions/4130486/spring-value-annotation-always-evaluating-as-null
반응형
해결
new ChargeUtil() 를 제거하고, 스프링이 관여할 수 있도록 @Autowired를 쓰도록 코드 수정
- ChargeUtil.java 를 bean으로 등록 (ex. @Component, @Service 등등)
- @Autowired를 사용해 ChargeUtil를 사용하면, 스프링이 관여하기 때문에 정상적으로 값을 불러온다
반응형
'개발 > 에러 디버깅' 카테고리의 다른 글
| (디버깅) Connection reset by peer 에러 원인과 해결 방법 (0) | 2022.07.31 |
|---|---|
| (JAVA) UnknownHostException 에러 : java.net.UnknownHostException (1) | 2022.07.24 |
| (JAVA) jar 파일실행시 File 사용 - java.io.FileNotFoundException (1) | 2022.01.18 |