API Gateway : 서버의 앞에서 모든 API 호출을 받아 인증후에 적절한 서비스에 라우팅(메시지 전달) => zuul + Eureka
Service Mesh
기능 : 마이크로 서비스 사이 통신 / 네트워크 제어
Service discovery, service routing , 트래픽 관리, 보안 을 수행
API Gateway와 비슷 (ex. Istio)
Container Management
컨테이너 기반의 어플리케이션이 유연성 및 자율성을 갖고, 개발자가 쉽게 접근/운영할 수 있어 MSA에 적합
Kubernetes(+Docker)가 가장 대표적인 컨테이너 관리 환경
Backing Services
실행중인 어플리케이션이 사용할 수 있는 모든 서비스 (DB, SMTP. 캐시 시스템과 통신하는 리소스들을 포함하는 개념 )
MSA에서는 Message Queue를 이용한 비동기 통신을 지향
그렇지 않는 다면 여러 서비스를 걸치는 실시간 트랜잭션 처리시, 하나의 서비스가 죽으면 트랜잭션이 끊김 -> 서비스 요청 보존 불가 & 에러 발생 따라서 데이터 변경 or 보상 트랜잭션에 관련된 처리는 Message Queue를 활용한 비동기 처리가 효율적 Kafka, rabbitMQ, AMQ
Telemetry
Tele(먼거리) + Metry(측정)
분산 환경에서 운영되는 MS의 상태를 일일이 모니터링/대응하기 어려움 => Telemetry가 서비스 모티너링 + 서비스별 이슈에 대응 하는 환경 구성
Logging + Monitoring + Tracing
Grafana, Prometheus, EFK, ELK 등의 OSS로 직접 구현
datadog 같은 사용 솔루션 사용
CI/CD Automation
CI : 지속적인 통합 , CD: 지속적인 전달/배포를 통해 배포가 잦은 MSA의 개발 단계를 자동화 => jenkins, gitlab
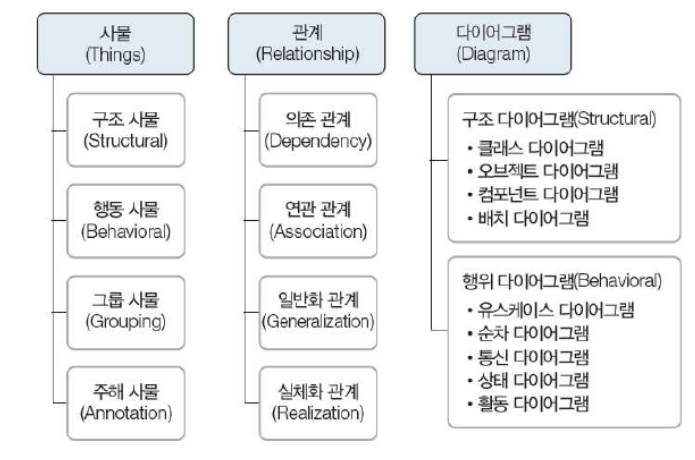
"The microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery."
small services(작은 서비스) each running in its own process(스스로 실행 가능) independently deployable(독립적 배포 가능)
-> 작고, 독립적으로 배포가능한 기능을마이크로서비스로나누어, 독립적인배포/ 다른기술스택을사용가능
출근길에 우연히 유튜브에서 '기억보단 기록'을 이라는 기술 블로그의 주인의 인터뷰영상을 보았다.
매일 자면서 가던 출근길이었지만 잠이깨고, 머리를 한대 맞은것 처럼 많은 생각이 들게 됐다.
개발자로서의 성장
지방대, 무스펙, 비전공자였지만 2년간 국비 학원을 다녀서 SI 직장에서 다니다가 한계를 느끼고 이직을 결심
매일 아침 2시간동안 공부하고 주말에도 알고리즘, 전공지식에 대해 꾸준하게 공부해서 ZUM 검색포털로 이직
거기서 혼자힘으로 만든 서비스의 코드 리뷰를 하는데, 기능이나 화면이 아닌 내부 성능(로직)을 가지고 평가를 받으면서 공부 방향이 많이 바뀌었고, 더 좋은 개발에 대해 고민을 많이 하셨다고 함. = 화면은 빨리 만드는건 당연한 거고, 더 좋은 구조로, 더 확장성 있는 구조로 만들 수 있을지에 대한 고민
회사에서 강의를 하면서 해당 내용을 스터디, 블로그로 정리하면서 활동하다가 배달의 민족으로 스카우트
원래는 트래픽이 많은 포털 사이트로 가기를 선호했지만, 한창 배민에 좋은 사람들이 많이 모이던 시절에 같이 일하고 싶어서 이직해서 오셨고 결국 배민이 짱 먹음ㅎㅎ
요즘들어 업무를 하다보면, 업무적인 실력은 좀 늘었지만, 과연 개발 실력은 ? 하는 생각이 든다 일인 만큼 업무처리는 당연히 빠르게 하고! 공부를 해야겠다는 생각이 부쩍 든다
더 좋은 소스& 확장하기 좋은 구조로 만들어야 겠다는 고민은 항상 가지고 개발하자!
전에는 원노트에 혼자만 정리했는데, 블로그에 쓰면서 한번 더 정리하고, 스터디도 병행하면서 더 내것으로 만들자
생각
무라카미 하루키의 생활패턴 : 무조건 하루 4시간만 작업하는 게 꾸준히 오래 할 수 있는 습관을 만들기 좋다
처음엔 5분짜리 시스템이 트래픽이 늘어서 16시간짜리 시스템이 됨 그때는 그 방식이 맞았을 수도.. 이전 방식으로는 해결할 수 없을 때는 새로운 기술, 새로운 구조로 아예 새로 만들어야 함.
그전까지의 무기로는 싸울 수 없는 상황 = 전쟁의 판도가 너무 빨리 바뀌므로 또 언제 전쟁의 상황이 바뀔지 모르니 남는 시간에 다른 무기에 대해 항상 공부
잡담이 경쟁력 : 옆에 자리가 있으면 항상 의자를 두고 누가 오든 대화를 해야 함 처음엔 힘들었는데 바로 피드백이 오기 때문에 훨씬 생산성이 좋다
IT업계는 전쟁의 무기가 계속 바뀌기 때문에, 꾸준히 개인적으로 공부하는 시간을 가져야만 한다!!
집념
1일 1 커밋 운동 : 업무시간외에도 사이드 프로젝트로 개인 공부를 하고 있음을 증명 심지어 갑상선암으로 입원하는 기간에도 예약을 걸어서 3년 동안 유지
하루에 80% 정도의 목표치만 채우고 나머지 20%는 내가 하고 싶은걸 하자 그게 쉬지 않고 스트레스를 크게 받지 않고, 번아웃이 오지 않는다
개발을 잘하는 유형은 2가지 사냥개처럼 어떻게든 결과를 물어오는 집요함 or 글 잘 쓰는 사람처럼 당연히 있어야 할 곳에 누구나 이해할 수 있게 코드를 작성
전체적인 인생은 제멋대로! 그때그때 하고 싶은걸 저지르자!그게 좋은 기회가 될 수 있다 목표는 내 범위에서만 나옴 => 목표를 정하면 다른 델 안 보니까 내가 생각 한길만 가게 됨
이 영상을 보고 매일 업무 처리만 급급하게 할게 아니라 여유가 있다면 20%의 남은 시간에 능동적으로 필요한 서비스를 개발&적용할 수 있도록 고민하자
같은 내용을 가져오더라도, 쿼리를 어떻게 작성했는지에 따라 쿼리의 성능이 차이가 생기겠죠.
데이터가 많아질수록 그 영향은 더 커질 겁니다.
그렇다면 쿼리를 작성할 때 기본적으로 고려하면 좋은 점들을 쿼리 초보자 입장에서 정리해보았습니다.
Select * 보다는 필요한 컬럼만 불러온다 => 서비스에서 나중에 쓰일 것 같은 컬럼을 일단 가져오고 서비스에서는 쓰지 않는 경우가 종종 있습니다. => 하지만, 모든 컬럼을 조회하면 그만큼 DB에 부담을 주기 때문에 필요한 컬럼만 가져오는 게 성능에 좋습니다.
Index를 타고 있는지 확인하자 => 정의된 index가 있는지, 있다면 index를 탈수 있도록 where절의 조건과 순서를 조정해서, index를 활용하는 편이 당연히 성능이 좋겠죠.
쿼리의 실행 순서를 기억하자. => From, On, Join, Where, Group, Having, Select, Order by 순서대로 실행됩니다. => 따라서 From, On, Join, Where, Having 순으로 Query가 확장될 때, 해당하는 대상을 줄여줄 수 있도록 작성해야 합니다. => 같은 조건이라도, having에 적용할 때보다, where절에서 필요한 만큼만 가져오는 게 성능이 더 좋다고 합니다. 그리고, 쿼리의 실행 순서가 ALIAS 순서이니까 알아두는 게 좋겠죠, (From 절에서 alias 하면 where절에서 사용 가능, Select에서 alias하면 where 절에서 사용 불가능)
Join 되는 결과 테이블의 크기를 줄여야 한다. => JOIN시 on절에 의해 추려지는 데이터는 메모리에서 관리하게 되므로, on으로 추릴 때 이왕이면 데이터의 중복이나, 양을 최대한 줄일 수 있도록 설정해야 성능에 도움이 된다고 합니다. =>그래서 Left outer join 보다는 inner join을 사용하자 같은 데이터를 뽑아낼 거면 Left outer join으로 null로 join 되는 걸 가져온 후 다시 제외하는 것보다, 한 번에 inner join을 사용하는 게 성능상 좋겠죠.
Where절에서 데이터 타입을 일치해야 한다. => Where id = '1'과 Where id = 1 이 있는데, id의 데이터 타입이 문자형이라면 인덱스를 활용할 수 있으므로 더 성능이 좋다고 합니다.
Distinct는 자제하자 => Distinct는 정렬에 따른 성능에 하락이 발생하기 때문에 필요한 경우에만 사용하는 게 좋다고 합니다.
Union 보다 Union all을 사용하자 => Union 은 중복 검사를 하기 때문에 성능 차이가 꽤 크게 납니다... 참고!